历史与渊源:
当计算机由美国人发明后,当时设计到字符输入,由于是英文字符,通过收集整理。他们形成了标准的ASCII码(128) 字符集。8位,首位为0。由于不断普及,欧洲西方国家相应使用,发现有些特殊字符它们不能表示,如:λφ等。如是出来想法,想利用 ASCII 码后128位,增加它们的字符。这样就出现了EASCII码。这些还是不能表示所有国家,像法语,俄语等有自己特殊字符。因此制定标准将后128位进行分片制定。制定出iso-8859系列字符集。
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
整出了这么多的字符集,说到底还是不够用;当计算机在中日韩等国家兴起的时候,这些字符集面对成千上万的中日韩字符,就显得有点力不从心了,像中国常见汉字有7000多个,扩展128个空位,完全不够。
因此,针对中文,需要用多个字节表示。第一个字节,第一位如果是1,后面还有一个字节与之一起表示一个字符。如果是0,就对应 ASCII 码。这样就形成了国内的GB2312,后来还是不够表示繁体中文,加入了繁体的字符形成了GBK;在GBK的基础上,又增加了6351个字符,其中一部分为4字节字(four-byte encoding range),增加了六种少数民族语言和一些四字节字,形成了GB18030-2000。
除了中文,全世界各个国家还是用它们自己字符集进行表示。没有一个统一的大字符集,能够表示全球所有字符。 同一台电脑上同时出现多国语言的字符时,就无法正常显示了。
在 1991 年,国际标准化组织和统一码联盟组织各自开发了 ISO/IEC 10646(USC)和 Unicode 项目。各自都想将项目作为世界标准,不过很快双方都意识到世界上并不需要两个不兼容的字符集。于是他们就编码问题进行了一次非常友好地会晤,决定彼此把工作内容合并,项目依然独立存在,各自发布各自的标准,前提是两者必须保持兼容。不过由于 Unicode 这一名字比较好记,因而它使用更为广泛,成为了事实上的统一编码标准。 此时此刻,世界就如大家想像般地合并了,天下大一统。
Unicode与UCS
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。 UTF-32/ UTF-16/ UTF-8 都是将数字转换到程序数据的编码方案。
我们平常所说的Unicode,通常是指Unicode字符集;从另一个层面来说,Unicode还有它的编码方案,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。
说完Unicode,就得再谈一下UCS和Unicode的关系; Unicode 字符编码标准与 ISO 10646 的通用字符集(Universal Character Set,UCS)概念相对应,从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。
UTF
Unicode(UCS)只是一个字符集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode(UCS)码是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题:
如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
为了解决这些问题,就出现了UTF。
UTF(Unicode Translation Format),它是Unicode (UCS)的实现(或存储)方式,称为Unicode转换格式。Unicode 的实现方式不同于编码方式。一个字符的Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。
UTF有三种实现方式:
UTF-16:需要1个或者2个16位长的码元来表示,是一个变长表示,与ASCII不兼容,其中BMP中的码位与UCS-2一致。
UTF-32:与UCS-4能表示的字一致,固定使用32 bits(四个字节)来表示一个字符。
UTF-8:最广泛的使用的UTF方案,UTF-8使用可变长度字节来储存Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。UTF-8更便于在使用Unicode的系统与现存的单字节的系统进行数据传输和交换。与前两个方案不同:UTF-8以字节为编码单元,没有字节序的问题。
UTF有三种方案,那么如何在接收数据和存储数据时识别数据采用的是哪个方案呢?
Unicode(UCS)规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte order Mark。
根据文件头的BOM,可以判断对应的文件编码。
EF BB BF ———— UTF-8
FE FF ————UTF-16/UCS-2, little endian
FF FE ————UTF-16/UCS-2, big endian
FE FF 00 00 ————UTF-32/UCS-4, little endian.
00 00 FF FE ————UTF-32/UCS-4, big-endian.
实例
大 Unicode编码为0x5927,可以通过Unicode中文编码表查到,用LoveString查看就是下图的结果:
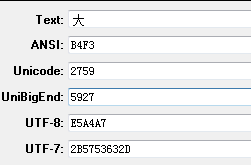
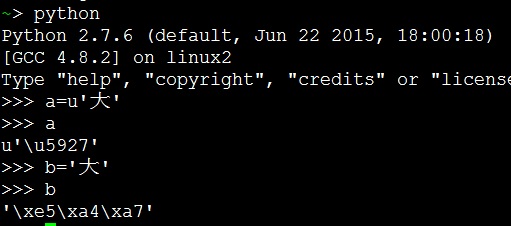
在Ubuntu中用Python查看,如下图:
最后我们将单个中文字‘大’,用编辑器存储成不同的编码格式,再仔细看看对应的二进制:
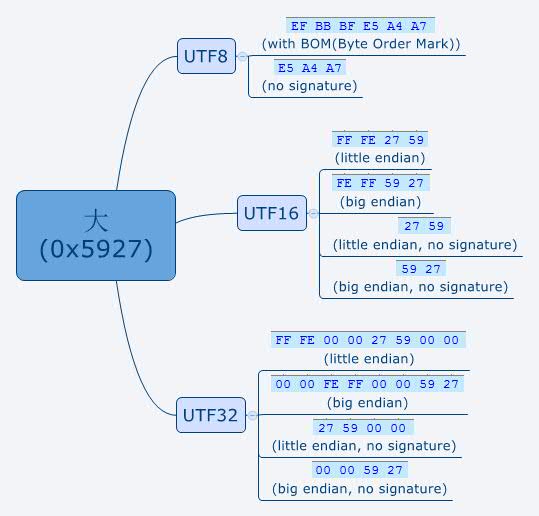
图中显示的BOM字符,就是按照上述所说的顺序来显示了。
以上就是关于字符集和字符编码的整理与个人理解,不一定完全正确,如果有什么错误的地方,还望海涵并指出,互相学习,积极思考。