逻辑回归
回归模型,作为机器学习的基本模型,上一次练习了线性回归,这次就说说Logistic Regression。
PyTorch代码实现
1 | import torch |
可以调整学习率、迭代次数、优化方法,看看不同的调整,会有什么不同的结果
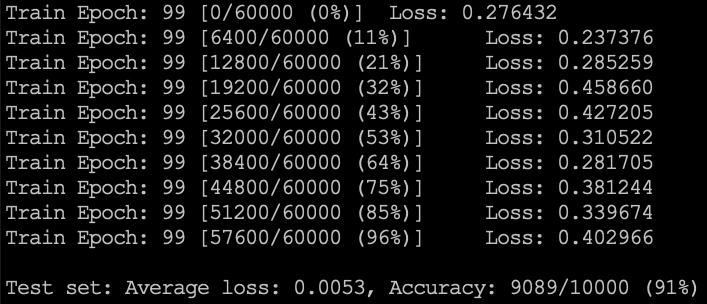
- 使用SDG,学习率为时,收敛速度有些慢,迭代了73次才达到,最终准确率稳定在$91\%$;
- 使用Adam,学习率一样为,收敛速度很快,一轮就能达到,接下来就是一直在 和 之间徘徊;
简单的回归,对于多分类还是心有余而力不足,后面会再用二分类练习逻辑回归,也会用神经网络来训练下MNIST数据集。
SDG训练了100次后的结果,如下图:
代码也可以查看我的GitHub仓库LogisticRegression,如有错误,欢迎指出。